Data Governance Software: Your 2026 Implementation Guide
Discover data governance software. Choose the right tool for your startup or mid-market team & implement for real ROI. Your practical 2026 guide.
https://www.youtube.com/watch?v=T9l00q-UF4Y
published
Outrank AI
data governance software, data governance tools, data management, data catalog, startup data stack
e820517d-568e-430d-9804-1c1eef709cf5

The usual moment is painfully predictable. Finance has one revenue number in a spreadsheet. Product has a different number in Mixpanel or Amplitude. Sales trusts the CRM export. The CEO asks a simple question in Slack, and three people spend half a day debating definitions before anyone answers.
That's the point where a growing company realizes it doesn't have a tooling problem alone. It has a trust problem.
Early on, teams get away with duct tape. One analyst knows where the clean tables live. One engineer knows which pipeline breaks every Monday. One operations manager keeps a “final_final_v3” sheet that somehow powers a board meeting. Then headcount grows, systems multiply, and those workarounds turn into drag. Analysts become ticket takers. Engineers become a human API. Business teams stop exploring because they don't trust what they'll find.
That's when data governance software starts to matter. Not as a procurement exercise. Not as a compliance-only project. As a way to make self-service work effectively.
If your team is already fighting duplicate metrics, broken dashboard logic, and unclear permissions, the fix usually starts with a tighter operating model and better tooling around quality. A useful place to start is this guide on improving data quality in practical ways. Governance only helps when the underlying data becomes easier to trust, not harder to access.
Table of Contents
What Is Data Governance Software Really
Hearing ‘governance' can evoke thoughts of approvals, restrictions, and process overhead. That's why so many rollouts fail before they start. In a healthy setup, data governance software does the opposite. It reduces friction by making data easier to find, easier to understand, and safer to use.
A simple analogy helps. Imagine it as the digital catalog for a large city library. The library doesn't just store books. It tells you what exists, where it came from, which edition is current, who can access restricted material, and whether the information is still reliable. Without that system, the library turns into a warehouse. You may have a lot of books, but no one can use them efficiently.
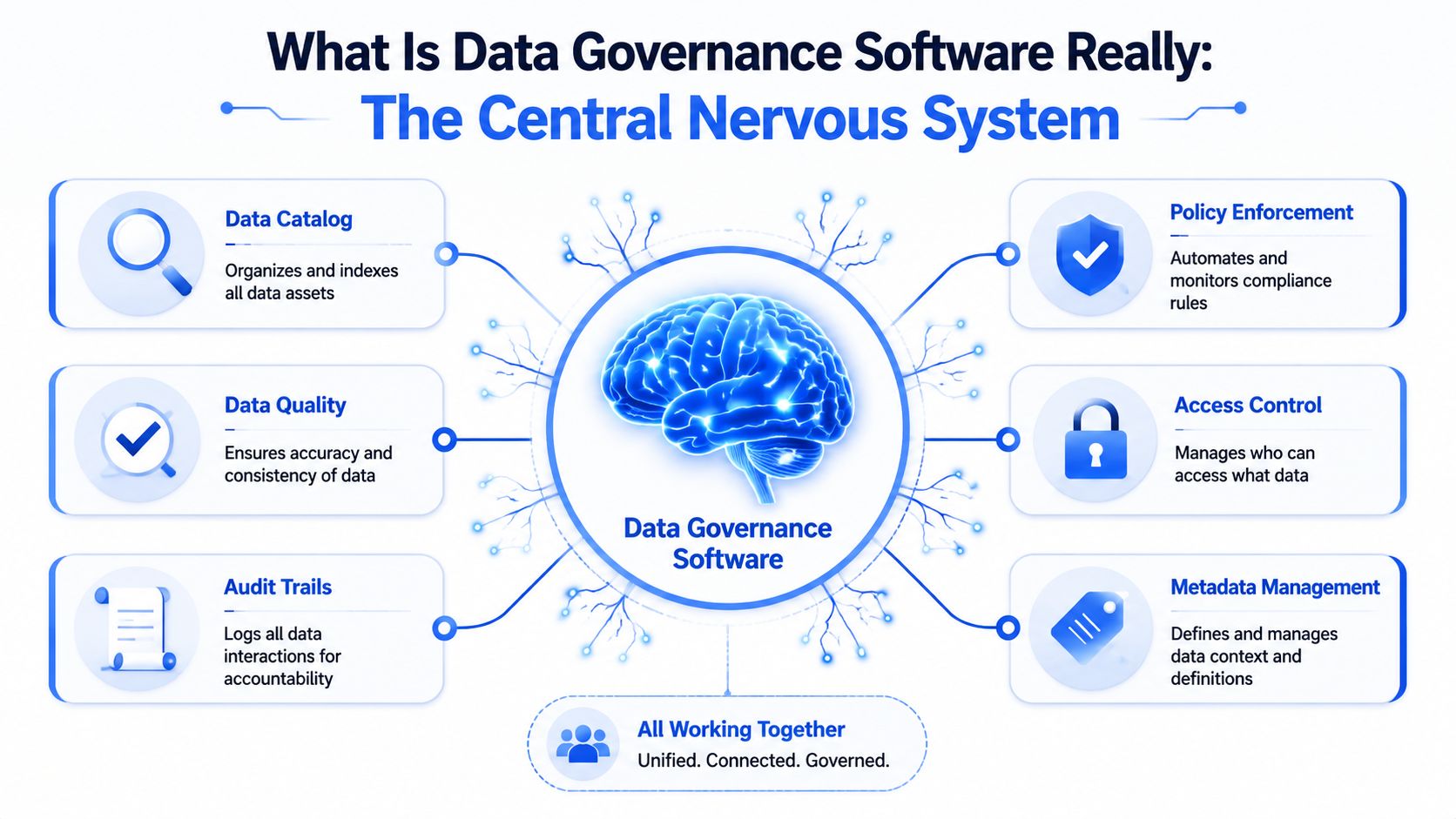
It's a control layer for trust
Good data governance software sits between raw data sprawl and daily business use. It helps teams answer practical questions fast:
What does this table mean
Who owns it
Can I trust it for a board deck or pricing decision
Who should have access
What breaks downstream if we change it
That's why the best teams don't treat governance as a legal or security side project. They use it to support reliable analytics, cleaner self-service, and faster decisions.
Practical rule: If governance only adds approval steps and documentation tasks, you don't have a governance program. You have extra admin.
It should increase access, not reduce it
This is the part startups often miss. Governance isn't about locking the warehouse and giving everyone a policy PDF. It's about creating enough structure that more people can use data without constantly asking analysts for help.
In practice, that means the software should help with metadata, definitions, ownership, and permissions in a way people can work with. A product manager should be able to find the trusted activation metric. A finance lead should know which revenue model is official. An engineer should be able to see what a schema change could affect before pushing it live.
The strongest implementations make this feel invisible. Users get search, context, and guardrails. Data teams get fewer interruptions.
For teams building a more usable data layer, a semantic layer primer for modern analytics stacks is often relevant because governance works better when definitions are standardized close to the warehouse.
The Four Pillars of Modern Data Governance Tools
A lot of tools claim to do governance because they catalog tables or manage permissions. That's too narrow. Effective platforms need four technical capabilities to keep data accurate and secure for analytics and AI workloads: automated data quality monitoring, end-to-end lineage visualization, role-based and attribute-based access controls, and effective integration across cloud and on-prem systems, as outlined in Databricks' guide to evaluating data governance platforms.
That list matters because each pillar solves a different operational problem. Lean teams need all four, even if they implement them in stages.

Quality checks that run without manual babysitting
The first pillar is automated data quality monitoring. That includes profiling, rule-based cleansing, and anomaly detection. The reason is simple. Most bad data isn't dramatic. It's quiet. A join changes. A field stops populating. A source starts sending nulls or malformed values.
If your team finds those issues only after a dashboard looks wrong, governance has already failed.
A lean team should start with a small set of checks on high-value assets:
Critical metric tables: Revenue, active users, pipeline, retention.
Sensitive records: Customer and employee data that need tighter controls.
Shared dimensions: Accounts, products, geographies, and user entities used across reports.
Lineage that answers where this number came from
Lineage is what turns a confusing metric dispute into a short investigation. It shows where a field originated, how it was transformed, and where it's consumed.
That matters for more than compliance. It's one of the fastest ways to reduce analyst thrash. When someone asks why the weekly active user metric shifted, the team should be able to inspect the path from source event to transformation to dashboard, instead of reverse-engineering SQL across five repos.
Teams trust a metric faster when they can inspect its history instead of taking someone's word for it.
Lineage also changes how engineering works. Schema changes become safer because the blast radius is visible before release.
Access control that protects data without creating queues
The third pillar is role-based and attribute-based access control, a point at which many implementations go wrong. Teams either make access too open and create risk, or too restrictive and force everything through data or security.
Good access control does neither. It aligns access with roles, domains, and sensitivity. Finance can work with finance data. Product can use behavioral data. People ops data stays restricted. Analysts don't become permanent gatekeepers.
A useful operating principle is to default to broad access for governed, documented, low-risk datasets and tighter controls for sensitive assets.
Integration that fits the stack you already have
The fourth pillar is integration. If the tool can't work with your warehouse, BI layer, orchestration setup, and transformation logic, it becomes another disconnected console no one checks.
For startups and mid-market teams, this is often the deciding factor. A lighter tool that connects cleanly to Snowflake, BigQuery, dbt, and common BI workflows usually beats an enterprise suite with deeper features but heavy setup.
Short version:
Pillar | What it prevents | What a lean team gets |
|---|---|---|
Automated quality | Silent data drift | Fewer downstream surprises |
Lineage | Metric confusion | Faster debugging and safer changes |
Access control | Risk or bottlenecks | Secure self-service |
Integration | Shelfware | Faster adoption |
Measuring the ROI of Data Governance
Leadership rarely objects to the idea of trusted data. They object to slow, expensive projects with fuzzy outcomes. If you want budget for data governance software, frame it around its operational effectiveness and efficiency.
The broader market direction supports that case. The global data governance software market reached USD 13.09 billion in 2025 and is projected to grow at a 15.27% CAGR from 2026 to 2035, reaching USD 40.81 billion by 2035, according to this market outlook on data governance software growth. You shouldn't use that as proof that a specific tool will pay off. You should use it as evidence that companies increasingly view governance as core infrastructure for data quality, privacy, security, and compliance.
What leaders actually care about
In startup and mid-market environments, ROI usually shows up in four places:
Analyst time gets redirected. Analysts spend less time answering repeated “which number is right” questions and more time doing actual analysis.
Engineering interruptions drop. Fewer emergency fixes happen when lineage and quality checks catch issues earlier.
Business teams move faster. Product, finance, and ops can self-serve on governed datasets instead of waiting in line.
Risk is reduced. Access policies and auditability make sensitive data easier to control.
None of those benefits requires a giant enterprise rollout. In fact, small wins usually produce the clearest ROI.
A lean ROI frame for smaller teams
Don't start by promising transformation. Start by measuring waste that everyone can already see.
Use a before-and-after frame such as:
Decision latency: How long it takes to answer a routine business question.
Data issue handling: How often broken definitions, undocumented tables, or access confusion trigger tickets.
Self-service reach: Whether more teams can answer their own questions using approved datasets.
Trust signals: Whether leaders stop asking for spreadsheet reconciliation before acting.
The missing piece in many governance efforts is the KPI layer. Semarchy notes that teams often skip defining goals and metrics at the start, and that buyer guides tend to focus on static features instead of ongoing monitoring systems with regularly reviewed KPIs in its article on data governance challenges and KPI gaps.
A practical companion framework is this guide to measuring ROI in AI and BI programs. The same logic applies here. Tie the tool to fewer manual handoffs and faster, more reliable decision-making.
Governance pays back fastest when it removes recurring work your best people hate doing.
A Pragmatic Implementation Roadmap
The fastest way to kill a governance initiative is to make it feel like a two-year architecture program. Startups don't need that. Most mid-market teams don't either. They need a narrow scope, clear ownership, and a rollout that improves speed within the first phase.
A simple roadmap works better than a grand strategy deck.

Phase one starts with ownership, not software
Pick a small number of critical data assets. Don't catalog everything. Start with the datasets and metrics that repeatedly create confusion or support important business decisions.
Then assign a named owner or steward for each one. This is essential. A governance platform without accountability is just software. Athena IT Solutions argues exactly that in its discussion of why data governance solutions fail without named ownership, noting that 52% of organizations face compliance audits and 40% receive non-compliance warnings when ownership isn't assigned.
The owner doesn't need to do all the work. They need to be accountable for definitions, quality expectations, and access decisions.
A lightweight phase-one checklist:
Choose one domain: Revenue, customer reporting, product engagement, or another area with repeated confusion.
Name owners: One accountable steward per critical asset.
Document only what matters: Business definition, source, refresh pattern, and who uses it.
Set a few rules: Access level, expected freshness, and basic quality checks.
Phase two turns a pilot into a repeatable system
Once ownership exists, add tooling that automates the repetitive parts. That usually means metadata capture, lineage visibility, quality monitoring, and access workflows.
At this stage, you're not trying to satisfy every possible governance requirement. You're trying to stop common failure modes from recurring.
This is also where many teams benefit from seeing a practical walkthrough of the concepts in action:
One question matters more than most vendor feature grids admit: How will you maintain efficient data while ensuring security and access for business teams? Semarchy highlights that exact blind spot in its piece on governance challenges, arguing that teams often focus on static tool features rather than ongoing monitoring and regularly reviewed KPIs.
Phase three and four scale what already works
Only after the pilot shows value should you expand coverage.
That expansion usually follows a pattern:
Phase | Focus | What success looks like |
|---|---|---|
Foundation | Critical assets and owners | Fewer disputes over key metrics |
Pilot | Tooling on one domain | Better visibility into quality and lineage |
Rollout | More domains and users | More self-service on approved data |
Optimization | KPI reviews and policy tuning | Governance becomes part of normal operations |
A few practical rules keep this lean:
Train by workflow, not theory: Show analysts how to trace lineage. Show domain owners how to review access.
Review KPIs regularly: Governance is maintained, not installed once.
Prefer defaults over exceptions: Standard labels, standard owner fields, standard access paths.
Add complexity only when demand is real: Most startups don't need a giant policy taxonomy in month one.
If you're evaluating tools in this stage, keep the focus on what helps teams query and work on governed warehouse data directly. Options in the market range from enterprise governance suites to lighter workflow-oriented products. Querio, for example, provides role-based access controls and a centralized semantic layer around warehouse-native analytics, which can fit teams that want self-service and governance closer to daily analysis rather than in a separate admin-heavy system.
Common Governance Pitfalls and How to Avoid Them
Governance projects usually don't fail because teams chose the wrong buzzword. They fail because the operating model stays vague while the tooling gets more elaborate.
The failures that show up most often
The first mistake is treating governance like an IT implementation. The tool gets purchased, connectors get configured, and everyone assumes the problem is solved. It isn't. If no one owns data definitions, quality standards, or access decisions, the old confusion just gets wrapped in a new interface.
The second mistake is choosing software far beyond the team's maturity. Enterprise suites can make sense in large, regulated environments. For a startup with one data engineer and a couple of analysts, they often create admin debt before they create value.
The third mistake is overcorrecting on control. Teams lock down too much, add request queues, and call it governance. Then business users go back to spreadsheets and side exports because official access is slower than unofficial workarounds.
A more reliable pattern looks like this:
Assign owners first: Every important dataset needs a named steward.
Govern the high-impact layer: Focus on the assets people use for decisions.
Keep access practical: Protect sensitive data, but don't force analysts to approve every harmless read.
Design for adoption: If business users can't search, understand, and use the system easily, they won't.
The strongest governance program is the one people keep using when no one reminds them.
One more issue is static rollout thinking. Teams launch policies and never revisit them. But governance drifts when the business changes. New metrics appear. New tools get added. New teams need access. The process has to adapt with the company.
The Vendor Selection Checklist for Modern Data Teams
By the time you're evaluating vendors, the main job isn't finding the platform with the longest feature sheet. It's finding the one your team will implement and keep using.
The pricing gap alone should force discipline. Improvado notes that enterprise-grade governance platforms such as Collibra or Snowflake Horizon typically cost $80,000 to $250,000 annually, and that successful selection depends on a structured evaluation tied to program needs and total cost of ownership in its guide to data governance tool pricing and evaluation.

Questions worth asking in every demo
Does it fit our stack: Ask how it works with your warehouse, transformation layer, and BI environment today.
Can we pilot it quickly: Time-to-value matters more than roadmap slides.
Will business users use it: Search, glossary, lineage views, and access flows should make sense outside the data team.
How does pricing scale: You need to understand license growth, services needs, and admin overhead.
What work stays manual: Many platforms automate cataloging but leave stewardship and policy operations messy.
Can it support self-service without exposing sensitive data: That's a critical test.
What happens when we outgrow the first use case: The platform should expand by domain, not require a reimplementation.
For teams debating platform choices, this buy-versus-build framework for analytics infrastructure is a useful complement. It helps separate core capabilities you should own from functions a vendor should handle.
The practical rule is simple. Buy the least complicated tool that solves the next real governance problem and leaves room for the one after that.
Querio fits teams that want governance to support warehouse-native self-service, not slow it down. If your analysts and business users are stuck waiting on a small data team, Querio provides AI-assisted querying, role-based access controls, and a semantic layer that can help turn governed data into something people can use every day.

