Mastering Multi-Touch Attribution Modeling: 2026 Guide
Master multi-touch attribution modeling. This essential guide helps data leaders choose, build, and evaluate models within modern data warehouses.
published
Outrank AI
multi-touch attribution, marketing analytics, data warehouse, data modeling, product analytics
fca6d232-5c27-4059-a1c3-c424553c0fe8

A familiar executive meeting goes like this. Finance asks why paid search looks indispensable in the dashboard, even though the team knows brand, content, email, product onboarding, and retargeting all played a role before the sale. Marketing defends top-of-funnel spend. Product points out that activated users often arrive after a long sequence of touches. The room has data, but nobody trusts the story.
That's the core reason to talk about multi-touch attribution modeling. Not because it's fashionable, and not because a vendor put “AI attribution” on a slide. The issue is simpler. If your measurement system gives all the credit to a single interaction, it will push budget toward whatever is easiest to observe, not necessarily what yields growth.
Leaders usually ask the wrong first question. They ask, “Which attribution model should we use?” The better question is, “Do we have the data discipline to build an attribution capability we can trust?” In a modern warehouse, multi-touch attribution modeling is less a reporting feature and more an operating system for how marketing, product, and finance reason about acquisition.
Table of Contents
Why Your Last-Click Model Is Lying to You
The most common attribution mistake isn't technical. It's organizational. A company cuts awareness spend because last-click reporting shows branded search or direct traffic “closed” the deal. A quarter later, pipeline softens, search efficiency worsens, and nobody can explain why. The report was clean. The decision was wrong.
Last-click does one thing well. It tells you which touchpoint happened immediately before conversion. That can be useful for operational reporting. It becomes dangerous when leadership treats it as a causal view of demand creation.
Roivenue reports that 70% of conversion journeys involve 2 or more touchpoints, and that 50%+ of revenue is affected by multi-touch measurement in the journeys it analyzes, which is a strong reminder that many conversions reflect a sequence of influences rather than a single decisive click (Roivenue's guide to multi-touch attribution models).
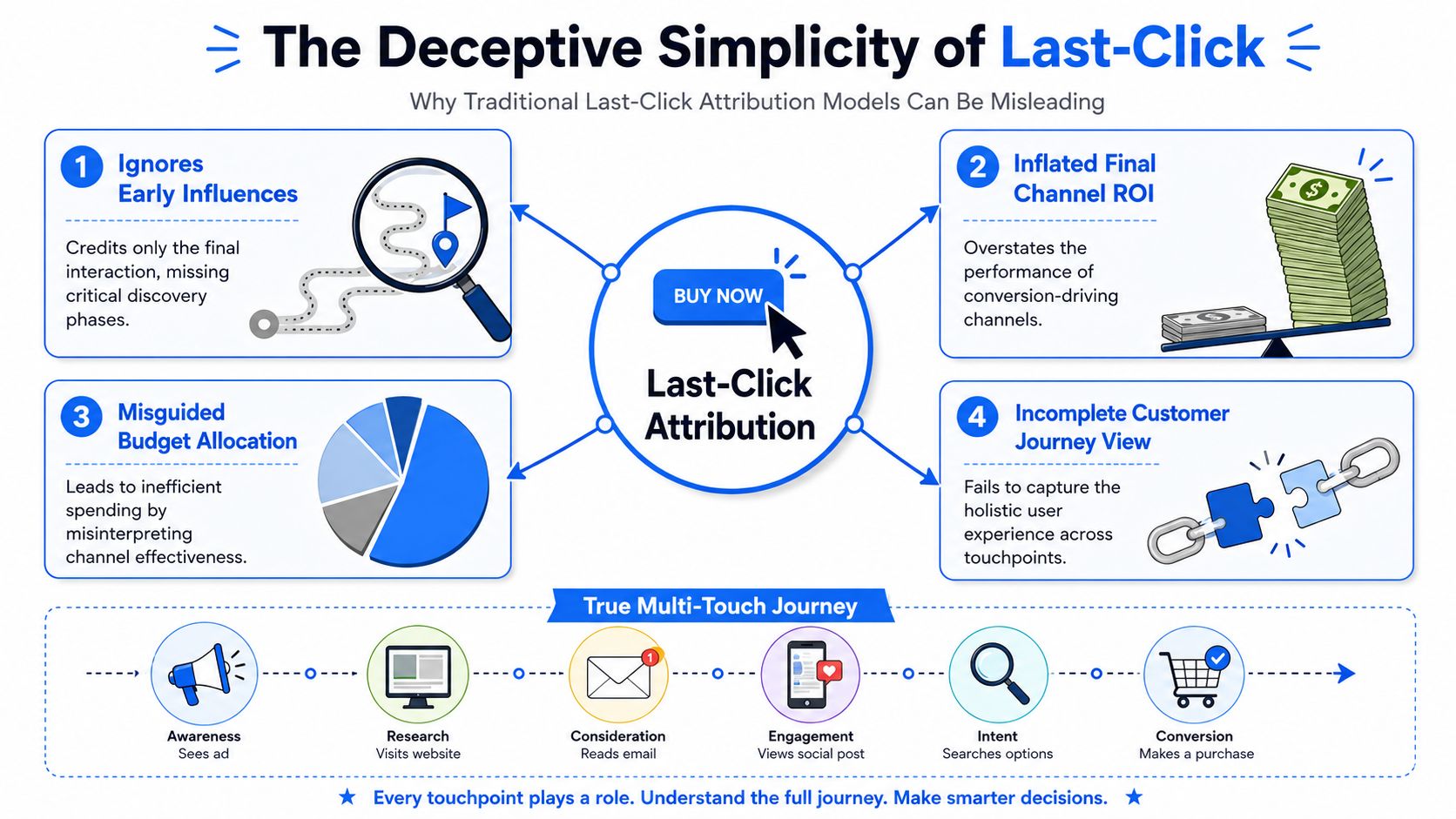
What last-click gets wrong
A buyer might first hear about you from a podcast clip, return through organic search, sign up for a webinar, receive a lifecycle email, compare vendors, then click a paid retargeting ad before buying. Last-click hands the win to retargeting. First-click hands it to the original discovery source. Both simplify a chain of influence into a single event.
That distortion changes behavior inside the company:
Marketing teams overfund closers because bottom-funnel channels appear to produce all the value.
Product teams lose context because acquisition quality gets disconnected from the journey that created intent.
Finance gets false confidence from neat dashboards that hide measurement bias.
Practical rule: If a model always makes the final channel look heroic, it's usually measuring observability, not contribution.
Leadership teams that care about CAC efficiency, channel mix, and forecasting need a broader frame than single-touch reporting. That's why attribution belongs in the same conversation as KPI design, not just campaign analytics. If your measurement logic can't reflect how buyers move, your board deck may be numerically precise and strategically wrong. For a related view on metric discipline, see how to measure key performance indicators.
Understanding Multi-Touch Attribution Concepts
Multi-touch attribution modeling assigns conversion credit across the interactions that influenced the outcome. The core idea is simple. A conversion path has multiple contributors, so the measurement system should distribute value across that path instead of giving everything to one touch.
A useful analogy is basketball. The scorer gets the points, but the possession may have depended on the outlet pass, the screen, and the assist. If you only credit the player who took the final shot, you won't understand how the offense works. Marketing journeys are similar.
The basic objects in the model
A few terms matter because teams often use them loosely:
Touchpoint means a recorded interaction tied to a person or account. That could be an ad click, email open, demo request, session, or sales activity.
Channel means the source category. Paid search, organic search, paid social, lifecycle email, partner referral, and sales outreach are all channels.
Conversion path means the ordered sequence of touchpoints that happened before a defined outcome.
Conversion event means the business outcome you care about. In different companies, that may be a purchase, trial start, qualified lead, or opportunity creation.
Those definitions sound basic, but they determine whether your analysis is actionable. If your “touchpoints” are inconsistent across systems, or your “conversion” is vague, attribution outputs won't survive executive scrutiny.
What the model is trying to answer
Attribution isn't trying to prove metaphysical truth. It's trying to support better decisions. It is often applied to answer questions like these:
Which channels introduce demand?
Which touches move buyers from interest to evaluation?
Which interactions consistently appear near conversion?
Which paths lead to higher-quality customers, not just more conversions?
That distinction matters. Good multi-touch attribution modeling doesn't just rank channels. It helps leaders understand sequences, handoffs, and dependencies across marketing, sales, and product.
Multi-touch attribution is most useful when it changes how teams allocate effort, not when it creates prettier dashboards.
Where leaders get confused
Many executives assume attribution is mainly a marketing problem. It isn't. Product shapes activation, sales shapes progression, and data engineering shapes what can be observed at all. In a warehouse-first setup, attribution is a shared analytical layer built on event data, CRM states, identity stitching, and business definitions.
That's why the practical unit of analysis isn't “campaign performance” alone. It's the customer journey as represented in your data model. Once leaders see attribution that way, the conversation shifts from buying a reporting tool to designing a durable measurement capability.
Rule-Based vs Algorithmic Attribution Models
A common executive failure mode looks like this. The team buys an attribution product, loads channel data, and gets a polished dashboard that claims paid social created pipeline, branded search closed it, and email assisted both. Nobody can explain the credit logic, finance does not trust the numbers, and budget decisions still fall back to last-click.
The decision is simpler. Choose whether to build an attribution capability your team can defend inside your warehouse, or buy a reporting layer that hides the assumptions.
Rule-based and algorithmic models answer the same question in different ways. Rule-based models assign credit according to logic you define in advance. Algorithmic models estimate contribution from patterns in observed journeys. One is easier to explain. The other can capture interaction effects that fixed weights miss. Neither is always better. The right choice depends on your path volume, identity quality, analytics maturity, and the level of scrutiny the output will face.
Rule-based models give you a usable operating model
Rule-based attribution is usually the right starting point for a warehouse-first team because the logic is inspectable. Analysts can express it in SQL, marketing can understand it, and executives can challenge the assumptions directly.
Salesforce describes a common position-based approach where the first and last touches receive most of the credit, with the remainder distributed across the middle interactions (Salesforce on multi-touch attribution). The exact percentages matter less than the governance model behind them. Everyone can see how credit is assigned.
That clarity makes rule-based models useful for:
Budget reviews where stakeholders need to understand why a channel gained or lost credit
Initial implementation in the warehouse before investing in heavier modeling
Benchmarking so more advanced models have a clear baseline to beat
There is a trade-off. Rule-based models encode your assumptions. If your buying journey changes, the model will not adapt unless your team updates it.
Algorithmic models can improve accuracy, if the inputs deserve it
Algorithmic attribution tries to estimate incremental contribution from observed path behavior instead of applying fixed weights. Common approaches include Markov chain models and Shapley value methods. Google's attribution documentation makes the core distinction clear: data-driven models assign credit based on each interaction's estimated contribution to conversion, using historical conversion paths rather than a fixed rule set (Google Analytics attribution models).
That sounds attractive because it is. In the right environment, algorithmic methods can pick up patterns that a linear or U-shaped model cannot. They can show that a touchpoint rarely closes deals on its own but consistently appears in paths that convert at higher rates.
They also fail in predictable ways.
If identity stitching is weak, if channel coverage is partial, or if journey volume is thin, the model will estimate contribution from an incomplete record of reality. The output often looks more credible than it is because the math is more complex than the inputs. I have seen teams spend months tuning model logic when the actual issue was that half the meaningful touches never reached the warehouse.
For teams building on a modern warehouse stack, infrastructure choice matters here too. Your attribution model is only as durable as the event pipeline, identity layer, and transformation patterns underneath it. That is one reason data warehouse architecture decisions affect attribution quality long before anyone debates Markov versus Shapley.
Executive trust usually breaks from hidden assumptions, not from simple models.
Comparison of Attribution Model Categories
Characteristic | Rule-Based Models (e.g., Linear, U-Shaped) | Algorithmic Models (e.g., Markov, Shapley) |
|---|---|---|
Credit assignment | Predefined weights | Estimated from observed path patterns |
Explainability | High | Lower |
Implementation effort | Lower | Higher |
Data requirements | Moderate | Higher |
Sensitivity to bad identity resolution | Significant | Significant, often worse in practice |
Best use case | Baseline measurement and operational reporting | More mature teams with stronger data foundations |
How to choose without wasting time
Start with a rule-based benchmark. It gives the business a shared reference point and exposes data issues early, before the team hides them inside a statistical model.
Add algorithmic attribution only when three conditions are true:
You have enough path volume to estimate contribution from real behavior rather than noise
Your identity and event coverage are stable across the channels that matter
You are prepared to validate the model against business decisions, not just model fit
Some teams should keep both. Use the rule-based model as the operating view for planning and reporting. Use the algorithmic model as a challenge model that tests whether your fixed assumptions are directionally wrong.
That is the strategic point leaders often miss. Multi-touch attribution is not a menu of models to pick from. It is a measurement capability you build in layers. The model choice matters, but the larger investment decision is whether your company has the data discipline, analytical capacity, and decision process to use the output well.
Building the Data Foundation for Accurate Attribution
A CEO reviews the quarter and sees paid search driving pipeline, email closing deals, and product-led signup doing a bit of everything. All three reports can be true at once if the underlying data is fragmented. That is why attribution work usually fails before anyone debates first-touch versus Shapley.
Accurate MTA starts with disciplined event collection, stable identifiers, and warehouse models that preserve the sequence of the customer journey. If those pieces are weak, the model will over-credit the channels you can observe cleanly and under-credit the ones that influenced demand earlier.
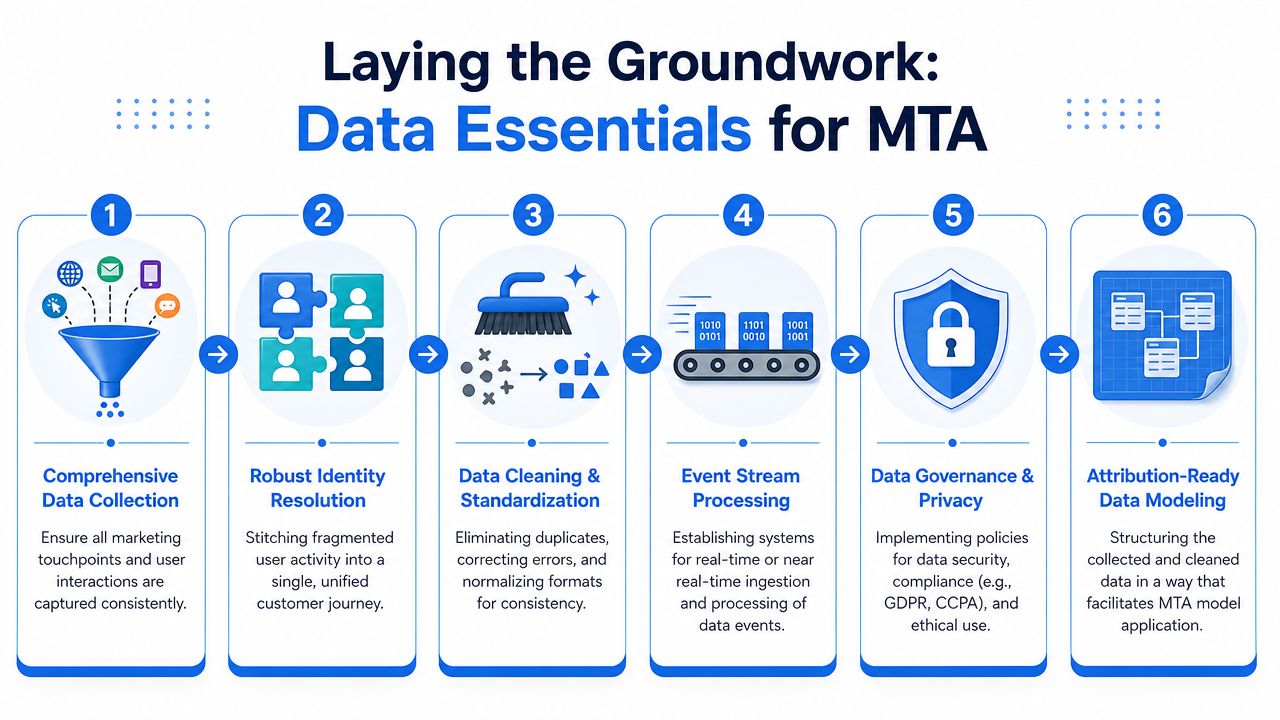
Event collection has to be boring and consistent
Attribution breaks under inconsistent tracking. Marketing may capture UTMs well, product may rename the same event three times in six months, and sales ops may change lifecycle stages without updating warehouse logic. The dashboard still fills up. The journey does not.
For MTA, the event layer usually needs four categories of data:
Acquisition events such as ad clicks, sessions, referral sources, and campaign metadata
Lifecycle events including signup, activation milestones, trial start, and upgrade intent
CRM state changes such as lead creation, qualification, opportunity creation, and closed-won markers
Identity signals like user IDs, email hashes, account IDs, and deterministic join keys
This sounds operational because it is. Attribution is not a BI project with a marketing label. It is a data product, and data products fail when definitions drift.
Identity resolution carries most of the accuracy burden
The same buyer often appears as multiple records before they become known. A mobile ad click creates one identifier. An email click creates another. A sales rep later creates a CRM contact tied to an account. If those records are never stitched together, the model treats one buying journey as several unrelated paths.
That creates a predictable bias. Late-stage touches get too much credit because they happen after identification. Earlier influence gets lost because it happened anonymously, on another device, or in a system that does not share keys cleanly.
A simple test helps. If the journey only becomes connected after a form fill or login, expect your attribution to favor lower-funnel channels, no matter how advanced the modeling looks.
Warehouse design determines whether attribution is auditable
Packaged attribution tools can produce attractive charts. They rarely give data teams enough control over join logic, timestamp rules, or business definitions to explain results under scrutiny. A warehouse-first approach does.
A workable setup usually includes:
A raw ingestion layer for ad, web, product, and CRM data
Standardized dimensions for channels, campaigns, and identities
A canonical touchpoints table with one row per attributable interaction
A conversion table with clearly defined business outcomes
A bridge layer that links touchpoints to conversions within an attribution window
The trade-off is straightforward. Building this in your warehouse takes more upfront work than buying a tool and loading connectors. It also gives you version control, reproducibility, and the ability to answer hard questions from finance, marketing, and product with the same underlying logic.
For leaders deciding whether MTA is worth the investment, this is the key point. You are not buying a model. You are building a measurement capability on top of your warehouse. If the core architecture is still fragmented, fix that first. This overview of data warehouse architecture patterns for analytics teams is a useful reference when planning that foundation.
Implementing MTA Models with SQL and Python Patterns
Once the data foundation is stable, implementation becomes much less mysterious. You don't need a black-box product to get started. You need a clean touchpoints table, a conversion table, and a repeatable way to apply attribution logic.
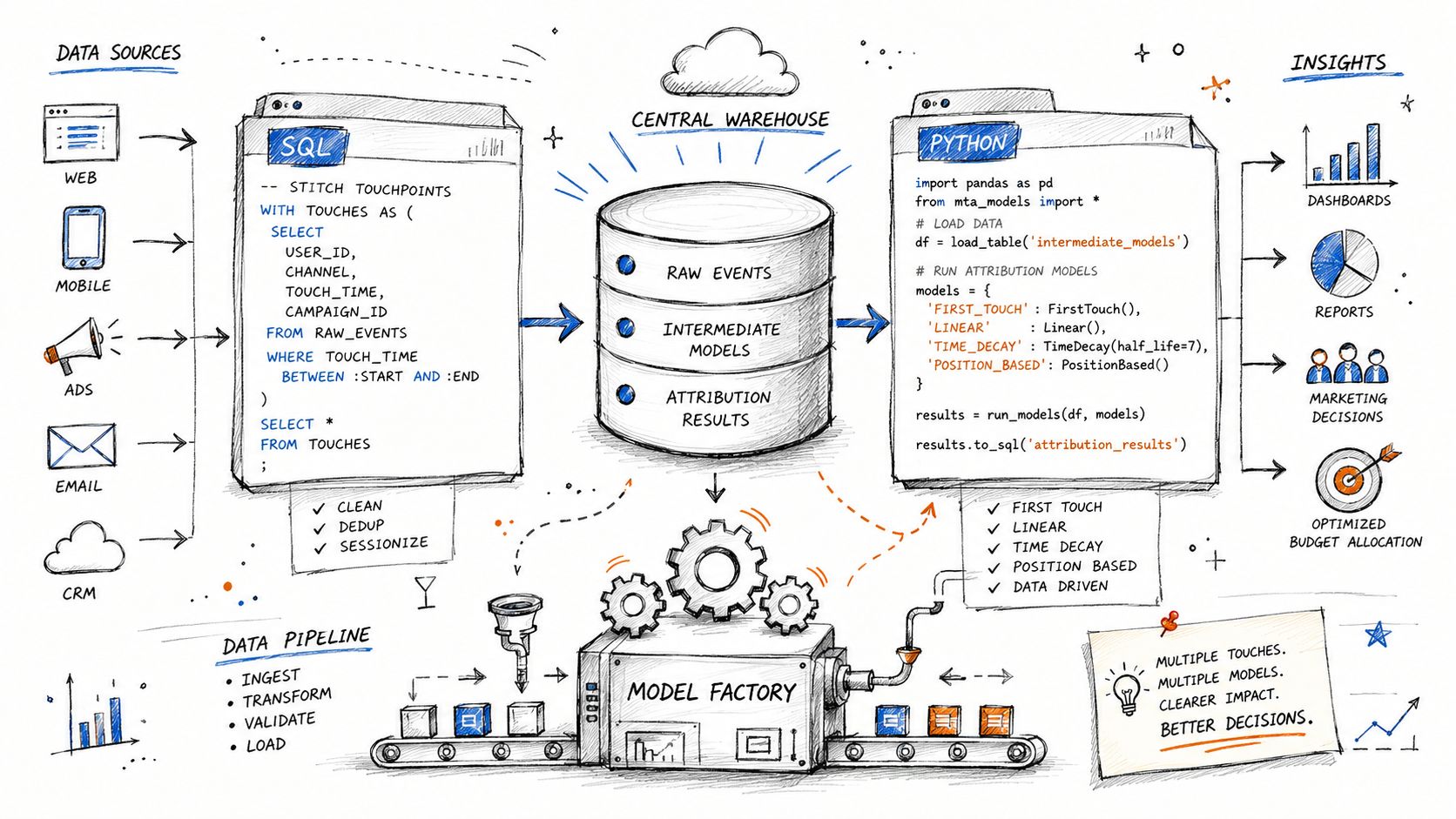
A practical warehouse pattern
At a high level, the implementation looks like this:
Ingest source data from tools like Segment, HubSpot or Salesforce, ad platforms, and your product database.
Normalize identifiers and timestamps.
Union all attributable events into a single table.
Link each conversion to prior touchpoints within a defined lookback window.
Apply the model logic and write credits back to a reporting table.
A conceptual SQL pattern might look like this:
This isn't production-ready code. It's the skeleton. In practice you'll add attribution windows, deduplication rules, session logic, and identity fallbacks.
A simple Python pattern for time-decay
Once the path table exists, Python is often the easiest place to experiment with model logic.
This pattern is useful because it keeps the model inspectable. Analysts can explain each step. Product and marketing leaders can challenge the decay logic. Everyone can trace channel totals back to raw paths.
What works in-house and what doesn't
The warehouse-centric approach works when the team is disciplined about definitions and ownership. It struggles when everyone wants custom exceptions.
Good implementation practice usually includes:
One canonical touchpoints model, not separate team-specific path tables
Versioned attribution logic so changes are documented
A challenge process for disputed channel credit
A notebook or code workflow where logic is reviewable by data peers
If your team is deciding where SQL should end and Python should begin, this breakdown of SQL vs Python is useful. In most MTA setups, SQL should build the path data and Python should handle experimentation, diagnostics, and more flexible modeling.
How to Evaluate and Trust Your Attribution Model
An attribution model earns trust the same way any decision system does. It has to be understandable, stable, and directionally useful when teams act on it.
The first check is stability. If channel credit swings wildly from one period to the next without any corresponding change in campaign mix, tracking, or go-to-market motion, the model is probably reacting to data quality issues rather than genuine shifts in buyer behavior.
Start with consistency before causality
Before anyone reallocates budget, ask a few plain questions:
Do repeated runs produce the same answer when the underlying data hasn't changed?
Do small data corrections create sensible adjustments rather than rewriting the whole story?
Do results line up with what operating teams observe in the field?
A model doesn't need to match everyone's intuition. It does need to survive contact with it.
If sales, growth, and product all say the model is impossible, stop defending the model and inspect the joins.
Use controlled business actions
The most practical validation method is selective action. If the model says a channel has low contribution, reduce exposure carefully and watch the downstream result. If it says a path pattern is unusually strong, reinforce that path and observe whether quality holds.
This isn't laboratory science. It's disciplined operating practice. You're looking for whether the model helps the company make better trade-offs than the old reporting view did.
A useful evaluation rhythm looks like this:
Review attribution output alongside pipeline and activation metrics.
Compare results across multiple lookback periods.
Investigate large changes before presenting them as strategic insights.
Make narrow budget or sequencing changes.
Check whether the observed result supports the model's directional guidance.
Tie outputs to business decisions
Attribution only matters if somebody uses it. Good teams translate model outputs into concrete actions:
Marketing adjusts spend mix, creative sequencing, and retargeting intensity.
Product identifies which acquisition paths produce users who activate cleanly.
Finance gets a more credible basis for efficiency conversations.
Leadership stops rewarding channels purely for being closest to the conversion event.
Trust also depends on upstream data hygiene. If the inputs are unstable, the outputs will be contested forever. Teams dealing with noisy source systems should tighten that first. This guide on how to improve data quality is relevant because attribution models are unusually sensitive to inconsistent event definitions and broken joins.
A Decision Framework for Adopting MTA
Your CMO wants a clearer read on channel performance. Your product leader wants to know which acquisition paths produce users who activate. Finance wants one number they can trust in the budget review. MTA sounds like the answer until the team realizes it needs consistent event tracking, usable identity stitching, warehouse models that can be audited, and someone to own the logic after launch.
That is why the first decision is not which attribution model to use. It is whether your company should build this capability at all.
Haus makes this point directly in their analysis of whether multi-touch attribution is worth it (Haus on whether multi-touch attribution is worth it). Privacy changes, weaker user-level identifiers, and fragmented platform data have made MTA harder to do well. For some teams, the right answer is still yes. For others, the honest answer is not yet.
When the investment makes sense
MTA earns its keep when it changes decisions that matter.
That usually means several conditions are true at the same time:
Your buying journey spans multiple systems and channels. Prospects may touch paid search, paid social, email, site content, product onboarding, and sales outreach before they convert.
The path to conversion is long enough that last-touch reporting creates bad incentives. Teams overfund closers and underfund the channels that create demand earlier in the journey.
Your warehouse already supports trusted reporting. If teams still argue over basic revenue or conversion definitions, MTA will create more debate, not clarity.
You can maintain identity and instrumentation over time. Someone needs to own UTM standards, event definitions, CRM joins, and the logic for person or account stitching.
Leaders are prepared to act on directional evidence, not pretend precision. MTA is most useful for budget allocation, sequencing, and channel role clarity. It is less useful if the organization expects a perfect answer at the individual touchpoint level.
In that setting, MTA becomes an operating capability built on your warehouse. That matters. You are not buying a black box and hoping the output is right. You are building logic your data team can inspect, explain, and revise as channels, tracking rules, and the product change.
When you should wait
Some teams should not invest yet.
If first-party tracking is weak, CRM hygiene is inconsistent, conversion definitions are still disputed, or no one has bandwidth to maintain the model, MTA will absorb time and still fail the credibility test. I have seen teams spend months building attribution logic only to keep using last-click dashboards in planning meetings because nobody trusted the joins.
In that situation, simpler measurement is better management. Use a narrower KPI set. Run cleaner experiments. Improve tracking coverage and identity rules first. A modest model that the company uses beats an advanced one that lives in a slide deck.
Good measurement is the most decision-useful model your data can support.
A CEO-level checklist
Before approving the investment, ask five direct questions:
Can we define the conversion events that matter to the business, without debate every month?
Can we connect touchpoints to people or accounts with reasonable confidence?
Do we have warehouse models the team can govern, inspect, and audit?
Will marketing, product, and finance change decisions based on the output?
Do we have named owners for data quality, identity logic, and model maintenance?
If the answer is yes to most of these, build MTA, but start with a simple, inspectable version and prove that it changes planning decisions. If the answer is no to several, do not force it. Fix the prerequisites first.
Querio helps data teams build capabilities like multi-touch attribution modeling directly on the warehouse instead of burying logic inside dashboards and disconnected tools. If your team wants a faster way to work in SQL and Python, create reusable analytics workflows, and give both technical and non-technical users self-serve access to trusted data, explore Querio.

